https://m.calendar.naver.com/#monthly/2021-03-24
네이버 캘린더
친절한 나의 스케줄 매니저
m.calendar.naver.com
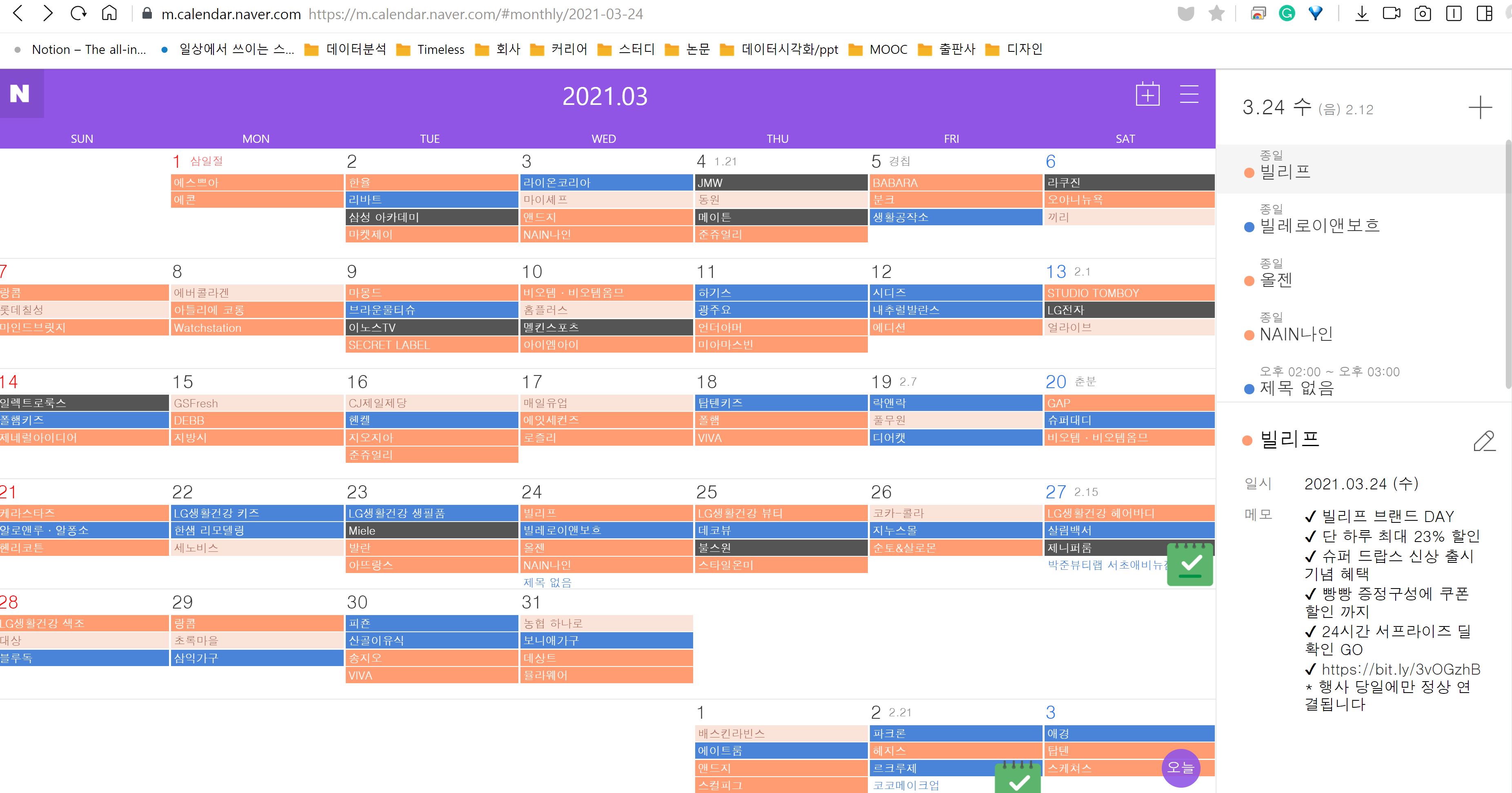
네이버 캘린더에 쇼핑캘린더 구독을 추가하면 네이버쇼핑의 이벤트들이 브랜드별로 캘린더에 추가된다.
진행되는 쇼핑이벤트 정보를 크롤링하여 DB에 적재해놓으면 물류/택배/수요예측 등을 분석할 때 사용될 수 있을 것이다. 크롤링하고자 하는 페이지와 정보는 다음과 같다.
- 이벤트 일정
- 브랜드 이름
- 행사 내용 (MEMO)
코드 전체
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import pyperclip
import bs4
from urllib.request import urlopen
from bs4 import BeautifulSoup
from html_table_parser import parser_functions as parser
from pprint import pprint
import requests
import getpass
import urllib.request
import random
from time import sleep
import numpy as np
import matplotlib.pyplot as plt
import datetime
from datetime import datetime, timedelta
import time
import sys
import os
import traceback
def ErrorLog(error: str):
current_time = time.strftime("%Y.%m.%d/%H:%M:%S", time.localtime(time.time()))
with open("Log.txt", "a") as f: f.write(f"[{current_time}] - {error}\n")
# In[2]:
try:
now = datetime.now()
nowDate = now.strftime('%Y-%m-%d')
after_one_day = now + timedelta(days=1)
after_one_dayDate = after_one_day.strftime('%Y-%m-%d')
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--incognito")
driver = webdriver.Chrome('C:/chromedriver_win32/chromedriver.exe')
# driver.get("https://nid.naver.com/nidlogin.login?svctype=262144&url=http://m.naver.com/aside/")
driver.get("https://m.calendar.naver.com/#monthly")
my_id = "~"
my_pw = "~"
pyperclip.copy(my_id)
xpath2 = '//input[@id = "id"]'
driver.find_element_by_xpath(xpath2).send_keys(Keys.CONTROL, 'v')
pyperclip.copy(my_pw)
xpath3 = '//input[@id = "pw"]'
driver.find_element_by_xpath(xpath3).send_keys(Keys.CONTROL, 'v')
xpath4 = '//input[@id = "log.login"]'
driver.find_element_by_xpath(xpath4).click()
# In[3]:
time.sleep(3)
# In[4]:
def date_time_to_str(dt):
year = str(dt.year)
month = str(dt.month)
day = str(dt.day)
if len(month) == 1:
month = '0'+month
if len(day) == 1:
day = '0'+day
return(year +'-'+ month+'-' + day)
# In[5]:
from datetime import datetime, timedelta
time1 = datetime(2019, 9, 24, 0, 0, 0)
time2 = datetime.now()
tomorrow = time2 + timedelta( days=1)
day_after_tomorrow = time2 + timedelta( days=2)
aa = tomorrow - time1
bb = day_after_tomorrow - time1
target_date_list = [date_time_to_str(datetime(2019, 9, 24, 0, 0, 0) + timedelta(days=i)) for i in range(aa.days+1)]
# In[6]:
target_date_list
# In[7]:
target_date_list[-1:]
# In[8]:
date_time_to_str(datetime(2019, 9, 24, 0, 0, 0))
# In[9]:
time.sleep(2)
# In[10]:
def get_Data(driver, target_date, nowDate):
result = []
time.sleep(2)
raw_info = driver.find_element_by_xpath('//*[@id="wrap"]/div/div[3]/div[1]/div')
a = raw_info.find_elements_by_tag_name('ul')[0]
b = int((a.text.count('\n') + 1)/2)+1
for i in range (1, b):
cal_dict = {'crawled_date':0,
'event_date':0,
'brand':0,
'memo':0,
'flag':0}
#처음 클릭 후 브랜드명 수집
try:
driver.find_element_by_xpath('//*[@id="wrap"]/div/div[3]/div[1]/div/ul/li[%s]/p' %i).click()
time.sleep(3)
brand = driver.find_element_by_xpath('//*[@id="wrap"]/div/div[3]/div[1]/div/ul/li[%s]/p/strong' %i).text
cal_dict['brand'] = brand
except:
cal_dict['brand']= 'null'
#memo내용 수집
try:
memo = driver.find_element_by_xpath('//*[@id="wrap"]/div/div[3]/div[2]/div[2]/div[3]/p[1]').text
cal_dict['memo'] = memo
except:
cal_dict['memo']= 'null'
#이벤트 날짜 수집
try:
event_date = driver.find_element_by_xpath('//*[@id="wrap"]/div/div[3]/div[2]/div[2]/div[1]/p/span').text
cal_dict['event_date'] = event_date
except:
cal_dict['event_date']= 'null'
#크롤링한 날짜
try:
cal_dict['crawled_date'] = nowDate
except:
cal_dict['crawled_date']= 'null'
#flag칼럼: 성공할 경우 'S', 실패한 경우 'F'넣기
try:
cal_dict['flag'] = 'S'
print('성공: 날짜: {date}, 진행률: {values}% '.format(date = target_date, values = (i/b)*100) )
except:
cal_dict['flag'] = 'F'
print('실패힝ㅠ: 날짜: {date}, 진행률: {values}% '.format(date = target_date, values = (i/b)*100) )
result += [cal_dict]
return result
# In[11]:
time.sleep(3)
final_result = []
for target_date in target_date_list[-1:]:
sleep(5)
driver.get('https://m.calendar.naver.com/#monthly/{target_date}'.format(target_date=target_date))
result=get_Data(driver, target_date, nowDate)
final_result += result
# In[12]:
pd.DataFrame.from_dict(final_result)
# In[13]:
import pymssql
server = '~'
database = '~'
username = '~'
password = '~'
cnxn = pymssql.connect(server, username, password, database)
cursor = cnxn.cursor()
# In[14]:
col_nm = str([i for i in final_result[0].keys()])[1:-1].replace("'","")
val_ct = str(['%s' for i in [i for i in final_result[0].keys()]])[1:-1].replace("'","")
sql = 'insert into NVR_SHP_CAL values ('+val_ct+')'
cursor.executemany(sql, tuple([ tuple(i.values()) for i in final_result] ))
## insert
cnxn.commit()
cnxn.close()
# In[15]:
time.sleep(3)
driver.quit()
except Exception as e:
#에러로그 메모장에 기록
err=traceback.format_exc()
ErrorLog(str(err))
#현재 날짜시각 가져오기
import datetime
from datetime import datetime, timedelta
now = datetime.now()
nowDate = now.strftime('%Y-%m-%d %H:%M')
nowDate
#에러 발생한 라인(예: 204)
lineno = e.__traceback__.tb_lineno
#에러 발생한 전체 메시지
err = str(err).replace("'","")
#에러 발생한 파일명
import inspect, os
a = inspect.getfile(inspect.currentframe()) #현재 파일이 위치한 경로 + 현재 파일 명
a_path = os.path.dirname(os.path.abspath(inspect.getfile(inspect.currentframe()))) #현재 파일이 위치한 경로
a_file = a.split("\\")[-1] #현재 파일 명
#TBL_EXCEPTION_ERROR 테이블에 에러 내용 INSERT
qu_templete = r'''insert into TBL_EXCEPTION_ERROR
(TABLE_NM, ERR_DATETIME, ERR_LINE, ERR_MSG, ERR_PATH_FILENM, ERR_PATH, ERR_FILENM)
VALUES
('%s','%s','%s','%s','%s','%s','%s' )'''
query = qu_templete % ('NVR_SHP_CAL',nowDate, lineno, err, a, a_path, a_file)
print(query)
cursor.execute(query)
cnxn.commit()
cnxn.close()
time.sleep(3)
driver.quit()